
چرخهی اجرای دستورالعمل در یک پردازنده
بحث خود را با روش کار یک پردازنده و کارهایی که این قطعهی سختافزاری قادر به انجام آن است، شروع میکنیم و خواهیم دید که چگونه بلوکهای ساختاری در یک طراحی عملیاتی گرد هم میآیند. این بلوکهای ساختاری شامل هستههای پردازنده، سلسلهمراتب حافظه، پیشبینیگر انشعاب (Branch Prediction) و دیگر اجزا است.
سادهترین توضیح پیرامون روش کار یک پردازنده، همان توضیح آشنایی است که به گوش همهی ما رسیده است. پردازنده از یک سری دستورالعمل برای انجام پارهای از اعمال روی مجموعهای از ورودیها پیروی میکند و نتایج خروجی را بازمیگرداند. این عملیات ممکن است شامل خواندن یک مقدار از حافظه، افزودن آن به مقداری دیگر و در نهایت بازگرداندن نتیجه به محل یا آدرس متفاوتی در حافظه باشد. محاسبه ممکن است پیچیدهتر نیز باشد؛ مثلا به کامپیوتر بگوییم اگر حاصل محاسبهی قبلی بیشتر از مقدار صفر شد، دو عدد را بر یکدیگر تقسیم کن.
معماری مجموعه دستورالعمل یا ISA مفهومی در ارتباط با برنامهنویسی است و زبانهای سطح بالا را به دستورالعملهای قابل درک برای پردازنده تبدیل میکند
برای اینکه برنامهای نظیر یک سیستمعامل یا یک بازی در کامپیوتر اجرا شود، آن برنامه که بهصورت مجموعهای از دستورالعملها در حافظه قرار دارد، برای اجرا در اختیار پردازنده قرار میگیرد. این دستورالعملها از حافظه بارگیری شده و در سادهترین حالت ممکن، یکی پس از دیگری اجرا میشود تا روند اجرای برنامه پایان یابد. توسعهدهندگان نرمافزار برنامههای خود را با زبانهای برنامهنویسی سطح بالایی نظیر C++ یا پایتون مینویسند که برای پردازنده بهصورت خام قابل درک نیست. همانطور که میدانید، پردازندهها فقط زبان صفرها و یکها را متوجه میشوند، پس باید راهی پیدا کنیم که دستورالعملها یا کدهای هر برنامه و نرمافزار به چنین فرمتی تبدیل شوند.
کدهای برنامه به مجموعهای از دستورالعملهای سطح پایین با نام زبان اسمبلی ترجمه (کامپایل) و تبدیل میشوند که بخشی از معماری مجموعه دستورالعمل (ISA) یا به اختصار معماری پردازنده است. این همان مجموعه دستورالعملهایی است که پردازنده برای درک و اجرای آن ساخته شده است. اصلیترین معماریهای مجموعه دستورالعمل یا به اختصار ISAها شامل x86، آرم، MIPS، معماری PowerPC و RISC-V میشود. زبانهای برنامهنویسی مختلف نحوهی نگارش و قرارگیری کلمات و عبارات و کدهای متفاوتی دارند که به آن سینتکس گفته میشود؛ همانطور که زبانهای سطح بالایی مثل C++ و پایتون سینتکس متفاوتی دارد، ISA هم سینتکس جداگانهای دارند.
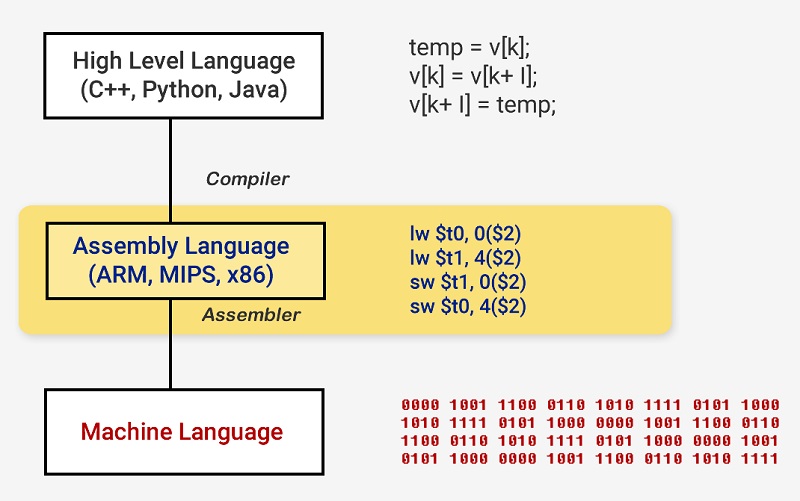 مراحل تبدیل کدهای سطح بالای یک برنامه به زبان ماشین
مراحل تبدیل کدهای سطح بالای یک برنامه به زبان ماشین
معماریهای مجموعه دستورالعمل به دو شاخهی اصلی قابل تجزیه است؛ طول ثابت و طول متغیر. معماری RISC-V از دستورالعملهایی با طول ثابت استفاده میکند؛ یعنی هر دستورالعمل تعداد بیت معین از پیش تعریفشدهای دارد که نوع آن دستورالعمل را تعریف میکند. در مقابل معماری x86 از دستورالعملهایی با طول متغیر استفاده میکند. در معماری x86، امکان رمزنویسی (Encoding) دستورالعملها با روشهای متفاوت و تعداد بیتهای مختلف برای بخشهای مختلف وجود دارد. به دلیل وجود چنین پیچیدگی، رمزگشایی (Decoding) دستورالعمل در پردازندههای x86 معمولاً با پیچیدهترین جزء در کل طراحی اجرایی میشود.
دستورالعملهای طول ثابت به دلیل ساختار متداول خود امکان رمزگشایی به مراتب سادهتری دارند، اما تعداد کل دستورالعملهایی را که یک ISA قادر به پشتیبانی از آن است، محدود میکند. در حالی که نسخههای متداول معماری RISC-V فقط چیزی در حدود ۱۰۰ دستورالعمل دارند و منبع باز هستند، معماری x86 یک دارایی فکری متعلق به اینتل است و و عدد دقیقی از تعداد دستورالعملهای این معماری در دسترس نیست. این باور وجود دارد که این معماری از چندهزار دستورالعمل پشتیبانی میکند؛ اما تعداد دقیق آنها اعلام نشده است. باوجود تفاوتهایی که در میان معماریهای مجموعه دستورالعمل وجود دارد، اصول زیربنایی تمامی آنها ضرورتاً یکسان است.
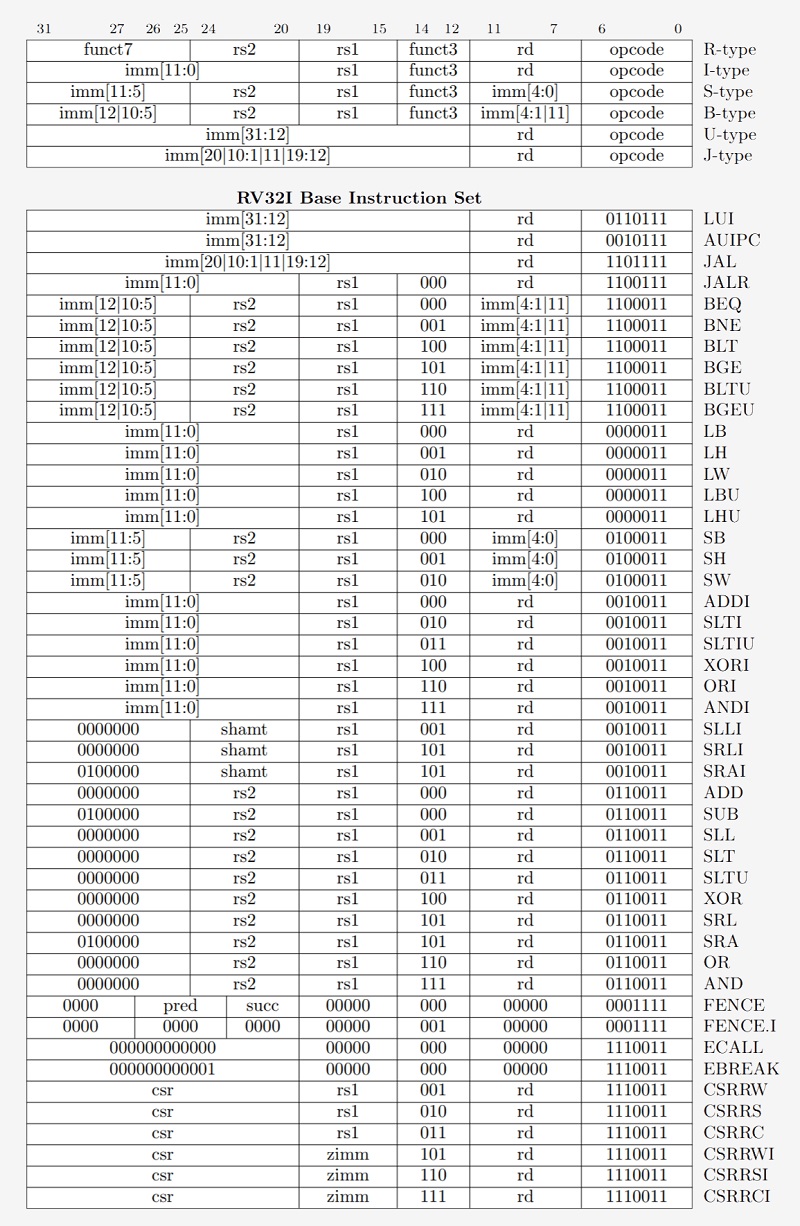 مثالی از دستورالعملهای مربوط به معماری RISC-V، کدهای عملیاتی (Opcode) نگارششده در سمت راست همگی ۷ بیتی (با طول ثابت) هستند و نوع دستورالعمل را تعیین میکند
مثالی از دستورالعملهای مربوط به معماری RISC-V، کدهای عملیاتی (Opcode) نگارششده در سمت راست همگی ۷ بیتی (با طول ثابت) هستند و نوع دستورالعمل را تعیین میکند
اکنون مروری بر نحوهی اجرای یک برنامه یا مجموعهی کدهای نوشتهشدهی آن توسط یک کامپیوتر خواهیم داشت. اجرای یک دستورالعمل در حقیقت شامل چند بخش اساسی است که در مراحل مختلف کار یک پردازنده به بخشهای کوچکتری تجزیه میشوند. در ادامه این بخشهای کلی با زبانی ساده تبیین خواهد شد.
اولین مرحله واکشی دستورالعمل (Fetch) از حافظه به پردازنده برای آغاز اجرا است. در مرحلهی دوم، دستورالعمل رمزگشایی (Decode) میشود تا پردازنده تشخیص دهد با چه نوع دستورالعملی سر و کار دارد. انواع زیادی از دستورالعملها شامل دستورالعملهای حسابی، دستورهای انشعاب و دستورالعملهای حافظه ممکن است برای اجرا در اختیار پردازنده قرار گیرد. به محض آنکه پردازنده دانست با چه نوع دستورالعملی سروکار دارد، عملوندهای (Operand) مرتبط با دستورالعمل از حافظه یا ثباتهای داخلی در CPU جمعآوری میشود. برای توضیح بیشتر، اگر بخواهیم طبق دستورالعمل، عدد A و عدد B را با یکدیگر جمع کنیم، تا زمانیکه مقادیر دقیق عملوندهای A و B مشخص نباشد، انجام عمل جمع ناممکن است. پس از آنکه پردازنده عملوندها را برای جایگذاری در دستورالعمل فراخواند، وارد مرحلهی اجرای دستورالعمل میشود که در آن عملیاتی روی مقادیر ورودی انجام میشود. این عملیات میتواند جمع اعداد ورودی، انجام یک عملیات دستکاری منطقی روی اعداد یا عبور دادن اعداد بدون اصلاح آنها باشد. پس از محاسبهی نتیجه ممکن است نیاز به دسترسی به حافظه برای ذخیرهی مقدار نتیجه باشد یا ممکن است پردازنده نتیجه را فقط در یکی از ثباتهای داخلی خود نگه دارد. پس از ذخیرهسازی نتیجه، پردازنده وضعیت المانهای مختلف را بهروزرسانی میکند و آمادهی اجرای دستورالعمل بعدی میشود.
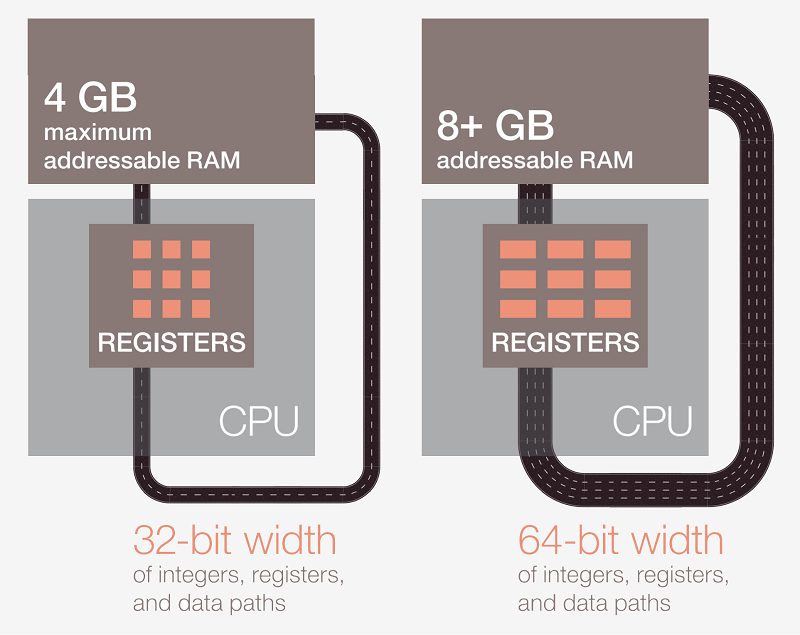
بیشتر پردازندههای مدرن ۶۴ بیتی هستند؛ یعنی مقادیر دادهها را با پهنای باند ۶۴ بیتی از آدرسهای حافظه و ثباتها فرا میخوانند و مورد پردازش قرار میدهند و نتایج پردازش را به آدرسهای حافظه باز میگردانند. بنابراین یک معماری پردازنده ۶۴ بیتی در مقایسه با یک مدل ۳۲ بیتی امکان فراخوانی و پردازش دو برابر داده را در آن واحد دارد.
توضیحاتی که در در مورد نحوهی عملکرد یک پردازنده ارائه شد، بسیار خلاصه و سادهسازی شده بود. بیشتر پردازندههای مدرن مراحل معدود یادشده را برای افزایش بازدهی به دستکم ۲۰ مرحلهی خردتر تقسیم میکنند. به عبارت دیگر، هر چند یک پردازنده در هر چرخهی کاری یا سیکل کلاک اجرای چندین دستورالعمل را شروع میکند، ادامه میدهد و به سرانجام میرساند؛ اما برای اجرای هر دستورالعمل از آغاز تا اتمام، ممکن است ۲۰ سیکل کلاک یا حتی بیشتر لازم باشد. به چنین مدلی در اصطلاح یک پایپلاین اطلاق میشود. پر شدن یک خط لوله با سیال در جریان مدتی به طول می انجامد، اما پس از آن یک خروجی پایدار و ثابت از آن سیال به دست میآید. در پایپلاین پردازنده، بهجای سیال دستورالعملها به جریان میافتند.
چرخهی کامل اجرای یک دستورالعمل فرایندی پیچیده و محاسبهشده است، اما این بهمعنای اجرای همزمان تمامی دستورالعملها نیست. برای مثال عمل جمع با سرعت بسیار زیاد اجرا میشود؛ اما عملیاتهایی مثل تقسیم یا بارگذاری از حافظه ممکن است صدها سیکل کلاک به طول بیانجامد. بهجای معطلکردن کل ساختار پردازنده برای اتمام یک دستورالعمل کنداجرا، بیشتر پردازندههای مدرن به نحوی بدون پیروی از نظم و ترتیب خاص کار میکنند. به عبارت دیگر پردازنده تعیین میکند که اجرای چه دستورالعملی در زمانی معین بیشترین سودمندی را دارد و در عین حال سایر دستورالعملهایی را که هنوز آماده اجرا نیست، بافر میکند. اگر دستورالعمل جاری هنوز آمادهی اجرا نباشد، پردازنده در خطوط کد به جلو پرش میکند و بهدنبال به بخشی از دستورالعمل که آمادهی اجرا است میگردد.
دستورالعملها بهمانند سیالی در پایپلاین پردازنده به جریان میافتد و در هر مرحله از پایپلاین، پردازش دستورالعملهای متعددی در جریان است
برخی از پردازندههای مدرن امروزی، علاوه بر اجرای نامنظم دستورالعملها، روشی با نام معماری سوپراسکالر را به کار میبندند. با این روش در هر زمان معین، پردازنده در حال اجرای دستورالعملهای بسیاری در یک مرحلهی خاص از پایپلاین (مثل مرحلهی واکشی، رمزگشایی، اجرا و ذخیرهسازی) است. در عین حال ممکن است پردازنده منتظر صدها دستورالعمل دیگر برای آغاز اجرا باشد.
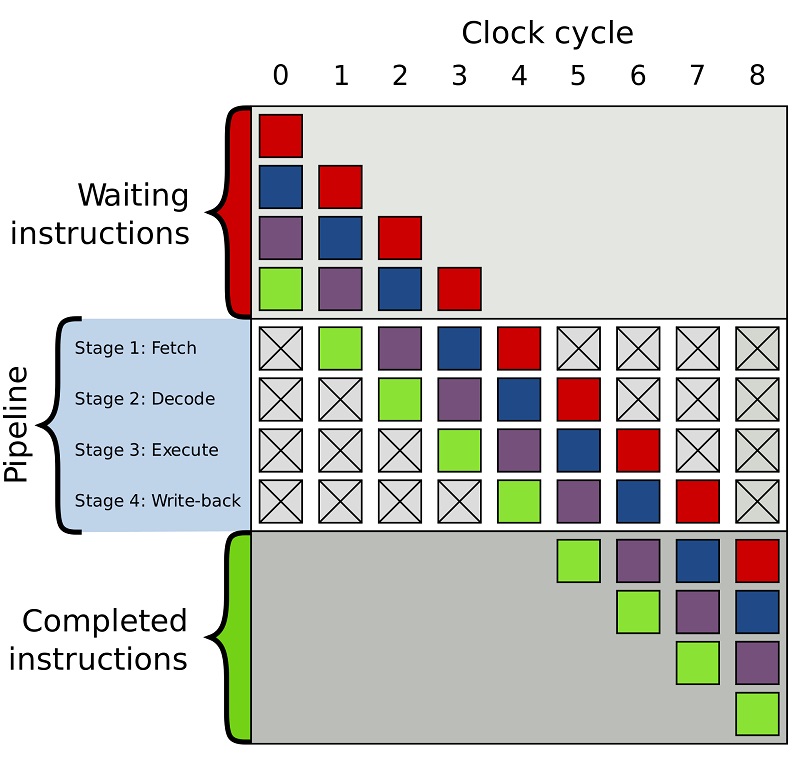 در شکل فوق، هر مربع رنگی نشاندهندهی یک دستورالعمل (کد) در پایپلاین، در انتظار ورود به آن یا اجراشده و خارجشده از پایپلاین است. در هر مرحله از پایپلاین کدهای متفاوتی در حال پردازش بوده و در عین حال ممکن است دستورالعملهای زیادی در بافر منتظر ورود به پایپ لاین باشند.
در شکل فوق، هر مربع رنگی نشاندهندهی یک دستورالعمل (کد) در پایپلاین، در انتظار ورود به آن یا اجراشده و خارجشده از پایپلاین است. در هر مرحله از پایپلاین کدهای متفاوتی در حال پردازش بوده و در عین حال ممکن است دستورالعملهای زیادی در بافر منتظر ورود به پایپ لاین باشند.
در اینجا بهتر است با مفهوم IPC که تأثیر بهسزایی در سطح عملکرد یک پردازنده دارد، آشنا شویم. IPC مخفف عبارت Instruction per Clock است که مفهوم آن میانگین تعداد دستورالعملهای اجراپذیر در هستههای پردازنده در هر سیکل کلاک است. محاسبهی IPC در یک ماشین کار نسبتا پیچیدهای است. برای انجام این کار مجموعهای بهخصوص از کدها برای اجرا به ماشین داده میشود و تعداد دستورالعملهای سطح ماشین برای تکمیل اجرای آن کدها محاسبه میشود. در گام بعد، با استفاده از زمانسنجهای سطح بالا تعداد سیکلهای کلاک موردنیاز برای کاملکردن آن تعداد دستورالعمل روی سختافزار واقعی اندازهگیری میشود. با تقسیم تعداد دستورالعملها بر تعداد سیکلهای کلاک اندازهگیریشده، رقم IPC ماشین مورد نظر محاسبه میشود. با ضرب IPC اندازهگیریشده در سرعت کلاک (بر حسب هرتز) و تعداد هستههای پردازنده، تعداد دستورالعمل اجراشدنی در هر ثانیه یا تعداد عملیاتهای ممیز شناوری محاسبه میشود که در هر ثانیه بهوسیلهی پردازندهی مدنظر اجراشدنی است. در نهایت، تعداد دستورالعملهای اجراشدنی بهوسیلهی پردازنده در هر ثانیه که با واحد گیگافلاپس یا میلیارد عمل اعشاری در ثانیه بیان میشود، معیاری از سطح عملکرد پردازندهی مدنظر است.
تعداد دستورالعملهای اجراپذیر در هر سیکل کلاک برای پردازنده عدد ثابتی نیست و بستگی به نحوهی تعامل و برهمکنش نرمافزار و برنامهی در حال اجرا با بخش سختافزاری سیستم دارد. با وجود این، طراحان تراشه سعی میکنند، با تکیه بر روشهایی مانند استفاده از چندین واحد محاسبهگر منطقی (ALU) در هر هسته و پایپلاینهای دستورالعمل کوتاهتر، عدد IPC را در مقایسه با مقدار متوسط آن افزایش دهند.
مجموعه دستورالعملها (Instruction Set) نیز بر عدد IPC پردازنده تأثیرگذار است. هرچه مجموعه دستورالعملها سادهتر باشد، IPC پردازنده افزایش مییابد و هرچه با دستورالعملهای پیچیدهتری روبهرو باشیم، بالتبع IPC کاهش پیدا میکند. بنابراین، IPC پردازنده برای اجرای محاسبات ممیز شناور با دقت واحد (FP32) در مقایسه با اجرای محاسبات با دقت مضاعف (FP64) عدد بزرگتری است. آنچه میزان کارایی پردازنده را مشخص میکند، ترکیبی از IPC و سرعت کلاک و تعداد هستهها است. با این حال، سازندگان پردازنده عموما عدد IPC را در مشخصات رسمی آن ذکر نمیکنند.
برای آنکه پردازنده بهطور همزمان قادر به اجرای دستورالعملهای زیادی باشد، ممکن است کپیهای زیادی از هر مرحله پایپلاین ایجاد کند. اگر پردازنده بداند که دو دستورالعمل بهطور هم زمان آمادهی اجرا است و وابستگی بین آنها وجود ندارد و نیازی به اتمام یکی و آغاز دیگری نیست، هر دو دستورالعمل را در یک زمان به اجرا در میآورد. یکی از راههای پیادهسازی این راهکار، پردازش چندرشتهای همزمان (Simultaneous Multithreading ) یا SMT است. پردازندههای اینتل و AMD در حال حاضر از شیوهی SMT دوخطی استفاده میکنند. در این پردازندهها هر هستهی فیزیکی به دو هسته مجازی تقسیمبندی شده و هر هستهی بهدستآمده یک ترد یا رشته نامگذاری میشود. بدین ترتیب هر هسته امکان اجرای دو جریان یا دو رشته دستورالعمل را بهطور همزمان خواهد داشت. IBM در حال توسعهی پردازندههایی با قابلیت اجرای SMT هشت خطی است.
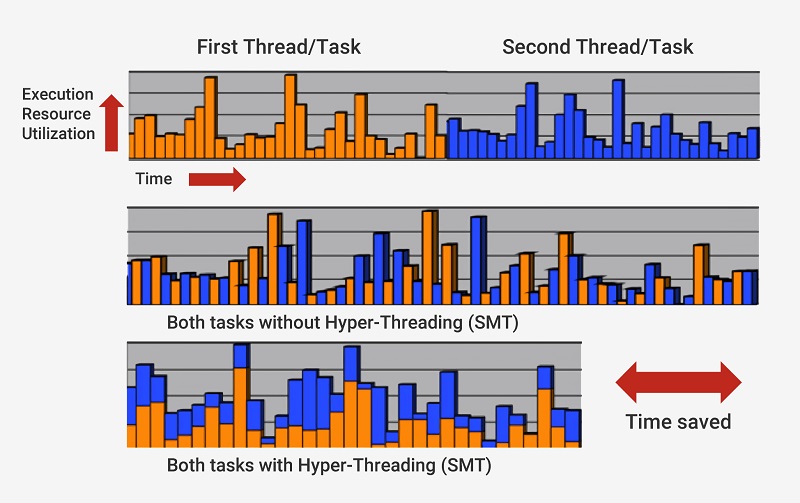 مولتی تردینگ یا پردازش همزمان چند رشته در هر هسته، باعث کاهش چشمگیر زمان اجرای دستورالعمل میشود
مولتی تردینگ یا پردازش همزمان چند رشته در هر هسته، باعث کاهش چشمگیر زمان اجرای دستورالعمل میشود
برای اجرای حسابشدهی چنین فرایندی، یک پردازنده علاوه بر هستههای اصلی از اجزای اضافی زیادی برخوردار است. صدها ماژول مجزا در یک پردازنده وجود دارد که هر یک هدف خاصی را برآورده میکنند. در این مقاله به جهت پرهیز از اطالهی کلام تنها به بررسی دو قسمت اصلی حافظه کش و پیشبینیگر انشعاب بسنده خواهیم کرد. اجزای دیگری نظیر بافرهای بازآرایی، Register Alias Table و ایستگاههای رزرواسیون وجود دارد که در این مقاله از توضیح آنها صرفنظر میشود.
مفهوم حافظهی کش ممکن است کمی گیجکننده باشد، چرا که آنها درست مثل رمِ سیستم یا درایو SSD دادهها را در خود ذخیره میکنند؛ اما آنچه باعث تمایز حافظهی کش از قطعات مشابه خود میشود، سرعت بسیار بالاتر و تأخیر کمتر در دسترسی به دادهها است. هر چند حافظهی رم سیستم بسیار سریع است، سرعت آن برای همگامشدن با فرآیندهای اجرای دستورالعمل پردازنده همچنان بسیار نارسا است. تأمین دادههای مورد نیاز پردازنده از سوی حافظهی رم ممکن است صدها سیکل کلاک به طول بیانجامد و امکان تغذیهی بههنگام پردازندهای که تنها در یک سیکل کلاک چندین دستورالعمل را اجرا میکند، با چنین سرعتی وجود ندارد. حالا اگر دادهها هنوز روی حافظهی رم قرار نگرفته باشد، دسترسی به دادههای مورد نیاز در حافظه SSD دهها هزار سیکل کلاک به طول میانجامد. بدون وجود حافظههای به مراتب سریعتر کش، پردازنده از کار باز خواهد ماند.
 سلسله مراتب و میزان تأخیر در دسترسی پردازنده به اجزای مختلف حافظه در سیستم
سلسله مراتب و میزان تأخیر در دسترسی پردازنده به اجزای مختلف حافظه در سیستم
پردازندهها بهطور معمول ۳ سطح از حافظهی کش را در خود دارند که بخشی از ساختاری با نام سلسلهمراتب حافظه را شکل میدهد. کش سطح ۱ (L1) کوچکترین و سریعترین حافظهی کش موجود در تراشه است، کش سطح ۲ (L2) از این نظر وضعیت متعادلی دارد و سومین سطح از حافظهی کش (L3) کندترین و بیشترین بخشِ حافظهی کش را به خود اختصاص میدهد. در سلسله مراتب حافظهی یک پردازنده، ثباتهای کوچک یک مرحله بالاتر از حافظهی کش قرار دارد که در خلال محاسبه یک مقدار دادهی واحد (۱ بیت) را به خود میگیرد. این ثباتها سریعترین تجهیزات ذخیرهسازی در یک سیستم کامپیوتری هستند که سرعت آنها چندینبرابر اجزای دیگر است. زمانیکه کامپایلر برنامه سطح بالا را به زبان اسمبلی ترجمه میکند، بهترین راه بهکارگیری این ثباتها را نیز تعیین میکند.
زمانیکه پردازنده دادهها را از حافظه فرامیخواند، ابتدا بررسی میکند آیا دادههای مورد نظر در حال حاضر در کش سطح ۱ قرار گرفته یا خیر. اگر دادههای مورد نظر در این کش قرار گرفته باشد، به سرعت و ظرف یکی دو سیکل کلاک در اختیار پردازنده قرار میگیرند. اگر دادهها در کش L1 قرار نگرفته باشند، پردازنده همین روال را در مورد کش سطح ۲ و سپس کش سطح ۳ پیگیری میکند. قطعات حافظهی کش به نحوی پیادهسازی میشود که محتوای آن برای هسته کاملاً شفاف باشد. هسته تنها دادهها را در آدرس مشخصی از حافظه درخواست میکند و هر سطحی از حافظهی کش که در سلسله مراتب، دادههای مورد نظر را در خود ذخیره داشته باشد بهسرعت پاسخ پردازنده را خواهد داد. با حرکت به سمت مراحل بعدی در سلسله مراتب حافظه، اندازه و میزان تأخیر حافظه عموماً تا چندین برابر افزایش مییابد. در آخر اگر پردازنده نتواند دادهها را در یکی از سطوح کش بیابد، به ناچار و با واسطهی جزیی از پردازنده با نام کنترلر حافظه، به حافظه اصلی (رم) مراجعه خواهد کرد.
در یک پردازندهی معمولی، هر هسته از دو جزء حافظه کش سطح یک برخوردار است؛ یکی از آنها برای ذخیرهی داده و دیگری برای ذخیرهی دستورالعملها استفاده میشود. ظرفیت کش سطح یک در مجموع حدود ۱۰۰ کیلوبایت است و اندازهی آن بسته به نوع تراشه، نسل و فناوری ساخت متغیر است. معمولاً هر هسته با یک کش سطح ۲ اختصاصی همراه میشود؛ گرچه گاه این قطعه از حافظه کش بین دو هسته به اشتراک گذارده میشود. ظرفیت کش سطح دو معمولاً از چند صد کیلو بایت تجاوز نمیکند. در نهایت کش سطح ۳ بین تمام هستهها به اشتراک گذارده میشود و ظرفیتی معادل چند ده مگابایت دارد.
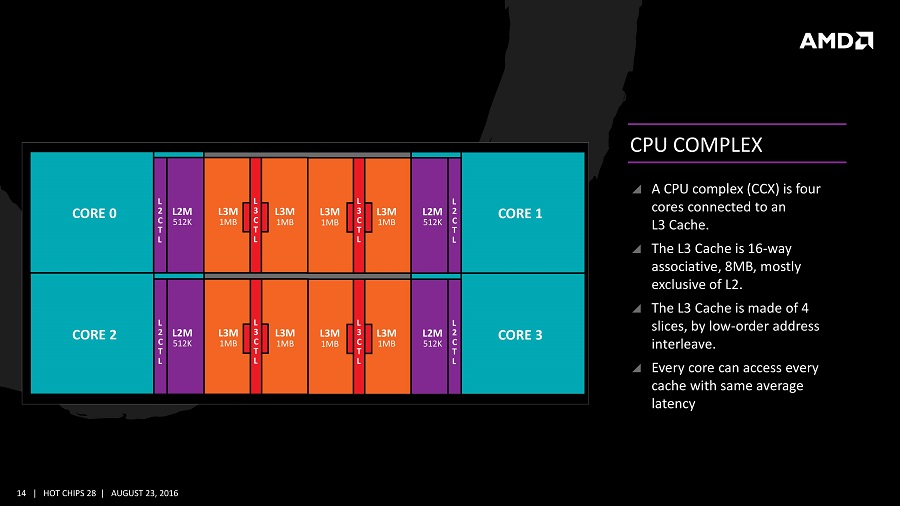 نحوهی توزیع حافظهی کش در بین هستههای پردازندهای با معماری ذن AMD
نحوهی توزیع حافظهی کش در بین هستههای پردازندهای با معماری ذن AMD
وقتی یک پردازنده در حال اجرای یک قطعه کد است، دستورالعملها و مقادیر دادهای که به آن نیاز است، در حافظهی کش ذخیرهسازی شده یا به اصطلاح کش میشود. با این شیوه سرعت اجرا بهطور چشمگیری افزایش می یابد؛ چرا که پردازنده برای دستیابی به دادههای مورد نیاز خود نیازی به تعامل دائمی با حافظهی اصلی ندارد. در مورد نحوهی قرارگیری حافظهی اصلی و SSD در زیر لایههای بعدی سلسلهمراتب حافظه، در ادامه بیشتر صحبت خواهیم کرد.
گذشته از حافظهی کش، یکی از بلوکهای ساختاری کلیدی هر پردازندهی مدرن بخشی است که پیشبینیگر انشعاب خوانده میشود. دستورالعملهای انشعاب شبیه به گزارهی «اگر» برای یک پردازنده است. اگر شرایطی برقرار باشد (If True)، یک مجموعه از دستورالعملها اجرا میشود و اگر آن شرایط برقرار نباشد (If False)، مجموعه دستورالعمل دیگری به اجرا گذارده میشود. برای مثال دو مقدار عددی با یکدیگر مقایسه میشود و اگر آن دو مقدار برابر باشد، عملیات معینی اجرا میشود. حال اگر این دو مقدار نابرابر باشد، بایستی عملیات دیگری اجرا شود. چنین دستورالعملهای انشعابی بهشدت در پایپلاین رایج بوده و ممکن است حداکثر ۲۰ درصد تمامی دستورالعملها را دربرگیرد.
این دستورالعملهای انشعاب در ظاهر ممکن است چندان مسئلهی مهمی به نظر نرسد، اما در عمل چالشی بر سر راه عملکرد درست یک پردازنده است. از آنجایی که پردازنده در هر مقطع زمانی ممکن است در حال اجرای ۱۰ یا ۲۰ دستورالعمل بهطور همزمان باشد، دانستن اینکه چه دستورالعملهایی باید به اجرا درآید، حائز اهمیت است. پنج سیکل کلاک برای شناسایی یک دستورالعمل انشعاب لازم است و ده سیکل کلاک دیگر باید طی شود تا مشخص گردد، آیا شرایط مورد نظر انشعاب برقرار هست یا نیست. در این بازهی زمانی، پردازنده ممکن است پردازش دهها دستورالعمل اضافی را بدون آنکه حتی بداند دستورالعملهای درستی (از نظر سازگاری با انشعاب) برای اجرا انتخاب شدهاند، آغاز کند.
برای غلبه بر این مشکل، تمامی پردازندههای ردهبالا از تکنیکی با نام Speculation استفاده میکنند. با این شیوه پردازنده با برخورداری از واحدی به نام پیشبینیگر انشعاب دستورالعملهای انشعاب را تعقیب میکند و حدس میزند که آیا انشعاب معین اختیار خواهد شد یا خیر. اگر این پیشبینی درست از آب در بیاید، پردازنده از قبل، اجرای دستورالعملهای پسآیند سازگاری را آغاز میکند و عملکرد تسریع میشود و بهبود مییابد. اما اگر پیشبینی نادرست باشد، پردازنده روند اجرا را متوقف میکند، تمامی دستورالعملهای نادرستی که اجرای آنها آغاز شده حذف میشود و مراحل اجرا از آخرین نقطهی درست، از سر گرفته میشود.
 طرح کلی معماری هستهی Zen 2 و جایگاه پیشبینیگر انشعاب (بلوک سبزرنگ) در آن
طرح کلی معماری هستهی Zen 2 و جایگاه پیشبینیگر انشعاب (بلوک سبزرنگ) در آن
پیشبینیگرهای انشعاب به نوعی پایهایترین اشکال یادگیری ماشین هستند؛ چرا که پیشبینیگر رفتار انشعابها را با جریان یافتن دستورالعملها در آن پیشبینی میکند. اگر پیشبینیگر به دفعات زیاد پیشبینی غلط انجام دهد، بهزودی رویکرد درست را خواهد آموخت. دههها تحقیق در مورد فنون پیشبینی انشعاب سبب شده است که در پردازندههای مدرن امروزی، در بیش از ۹۰ درصد موارد پیشبینیهای درستی انجام شود. تکنیک Speculation پردازنده را قادر به اجرای دستورالعملهایی میکند که بهجای قرار گرفتن در صفوف شلوغ داده، از قبل آمادهی پردازش است؛ در عین حال پردازنده را در معرض آسیبهای امنیتی نیز قرار میدهد. حفرهی امنیتی مشهور Spectre حملات خود را از راه پیشبینیگر انشعاب و با نفوذی مبتنی بر Speculation تحمیل میکند. بنابراین برخی از جنبههای این تکنیک باید بازبینی و بازطراحی شود تا از نفوذ دستورالعملهای غیر ایمن در پایپلاین و نشتی اطلاعات حافظه جلوگیری به عمل آید؛ حتی اگر تأثیر کوچکی بر سطح عملکرد بگذارد.
معماریهای مورد استفاده در پردازندههای مدرن، راهی دراز و پرفرازونشیب در خلال دهههای گذشته پیموده است. ابداعات و طراحیهای هوشمندانه منجر به بهبود عملکرد و بهکارگیری بهتر اجزای ناپیدای سختافزاری میشود. تراشهسازان در مورد جزئیات فناوریهای بهکاررفته در روند ساخت پردازنده بسیار رمزآلود عمل میکنند و دانستن آنچه که دقیقاً درون یک پردازنده و در خلال اجرای دستورالعملها اتفاق میافتد، ناممکن است. با وجود این اصول کار پردازندههای کامپیوتر و استانداردهایی که در روند اجرای محاسبات در پردازندهها رعایت میشود، نسبتا مشخص است. ممکن است اینتل دست به اقدامی مخفیانه برای بهبود عملکرد حافظهی کش خود بزند یا AMD از یک واحد پیشبینیگر انشعاب پیشرفته با کارایی بهتر استفاده کند، اما در مجموع هر دو دست به اقدامات مشابهی میزنند.
آشنایی با عناصر سازنده و اجزای یک پردازنده
اکنون که با روش کار پردازندهها آشنا شدیم، وقت آن است که وارد لایههای عمیقتر پردازنده شویم و با اجزا و بخشهای داخلی آن آشنایی بیشتری پیدا کنیم. همانطور که احتمالا میدانید، پردازندهها و دیگر مدارات دیجیتالی مجتمع از اجزایی با نام ترانزیستور ساخته شدهاند. ساده ترین راه برای داشتن درکی از یک ترانزیستور تصور سوئیچی با سه پایه یا پین است. گیت منطقی وسیلهای الکترونیکی مرکب از یک یا چند ترانزیستور است که عملیات منطقی را روی دادههای باینری (مرکب از ۰ و ۱) انجام میدهد. زمانیکه گیت باز باشد، امکان عبور جریان الکتریسیته از درون ترانزیستور وجود دارد و با بستهشدن گیت، جریانی عبور نخواهد کرد. ترانزیستور درست بهمانند کلید برق روی دیوار عمل میکند، اما بسیار کوچک تر و بسیار سریعتر است و توانایی کنترل جریان را نیز دارد.
در پردازندههای مدرن دو نوع ترانزیستور اصلی به کار میرود: نوع pMOS و نوع nMOS که به اختصار به آن انواع p و n نیز گفته میشود. ترانزیستور nMOS با شارژ شدن گیت یا تنظیم حالت High، امکان عبور جریان را فراهم میکند و ترانزیستور pMOS جریان را در صورتی عبور میدهد که گیت دشارژ شده یا روی حالت low تنظیم شود. با ترکیب این دو نوع ترانزیستور به طوری که یکی مکمل دیگری باشد، امکان ساخت گیتهای منطقی CMOS وجود دارد. در این قسمت از مقاله قصد نداریم وارد جزئیات فنی و ظریف نحوهی کار ترانزیستورها شویم.
گیت منطقی یک وسیلهی ساده است که ورودی را دریافت کرده، عملیاتی را روی آن اجرا میکند و نتیجه را بهعنوان خروجی به دست میدهد. برای مثال یک گیت AND خروجی خود را اگر و تنها اگر همه ورودیهای گیت روشن باشد، روشن خواهد کرد. یک گیت NOT یا وارونگر (Inverter) خروجی خود را در صورتی روشن میکند که ورودی خاموش باشد. با ترکیب این دو گیت، یک گیت NAND یا NOT-AND تشکیل میشود که اگر و تنها اگر هیچ یک از ورودیها روشن نباشند، خروجی خود را روشن میکند؛ البته گیتهای دیگری نظیر XOR ،NOR ،OR و XNOR نیز در مدارهای منطقی یافت میشود. در ادامه خواهیم دید که چگونه دو نوع گیت اساسی منطقی وارونگر و NAND با استفاده از ترانزیستورها طراحی میشود.
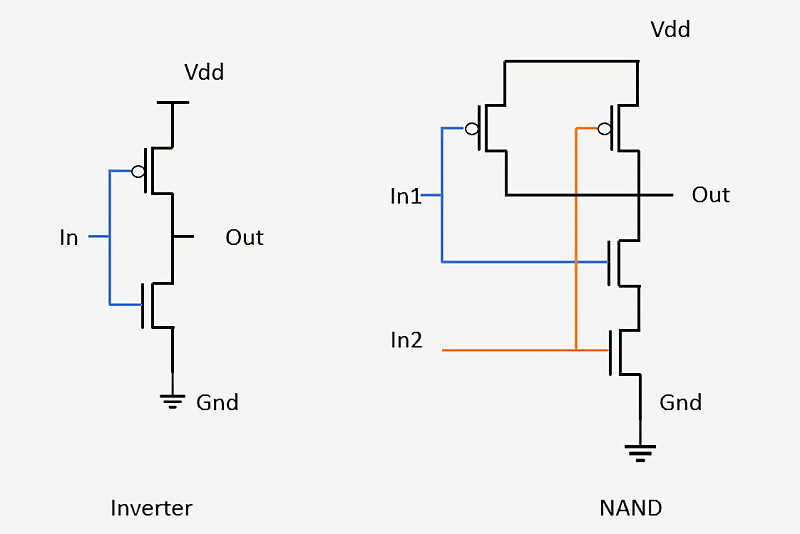 گیتهای منطقی NAND و وارونگر ترکیبی از سیگنالهای ورودی، خروجی، ترانزیستورها و البته اتصال زمین است
گیتهای منطقی NAND و وارونگر ترکیبی از سیگنالهای ورودی، خروجی، ترانزیستورها و البته اتصال زمین است
در گیت وارونگر، یک ترانزیستور نوع pMOS در بالای گیت قرار میگیرد که به خطوط حامل توان متصل است و یک ترانزیستور nMOS در پایین گیت نقش اتصال زمین را بازی میکند. ترانزیستورهای pMOS را روی نقشه مدار با دایرهی کوچکی که به گیت خود متصل است، نشان داده شده و ترانزیستورهای nMOS تنها به شکل یک پارهخط کوچک عمودی بیان میشود. از آن رو که ترانزیستورهای pMOS با خاموش بودن ورودی، جریان را عبور میدهند و ترانزیستورهای nMOS در صورت شارژ ورودی اقدام به هدایت جریان میکنند، میتوان دریافت که سیگنال در Out (خروجی) گیت همواره مخالف سیگنال در In (ورودی) است.
در گیت NAND چهار ترانزیستور مختلف وجود دارد و امکان تغذیه با دو ورودی فراهم است. مادامی که دستکم یکی از ورودیها خاموش باشد، خروجی گیت روشن است. اتصال ترانزیستورها در قالب شبکههای ساده نظیر گیتهای یادشده، همان فرآیندی است که برای طراحی گیتهای منطقی بسیار پیچیده و مدارات تعبیهشده در یک پردازنده، مورد استفادهی مهندسان تراشهساز قرار میگیرد.
با بلوکهای ساختاری بهسادگی گیتهای منطقی، داشتن درکی از نحوهی ترکیب و تبدیل آنها به یک تراشه محاسبهگر پیشرفته شاید سخت به نظر برسد. فرایند طراحی چنین تراشههایی در برگیرندهی ترکیب گیتهای متعدد برای ساخت مداری کوچک است که توانایی انجام یک عمل محاسباتی ساده را دارد. پس از آن تعداد زیادی از این مدارهای کوچک ترکیب میشود تا ساختاری برای انجام یک عمل پیچیدهتر به دست آید. فرایند ترکیب اجزای جداگانهی سادهتر نظیر انواع گیتهای منطقی و ترکیب آنها برای دستیابی به یک طراحی عملیاتی و در نهایت مدار مجتمعی که قادر به اجرای محاسبات پیچیده با سرعت بسیار بالایی باشد، دقیقا همان شیوهای است که امروزه در ساخت پردازندههای مدرن کاربرد دارد. یک تراشهی امروزی ساختاری مرکب از مدارهای منطقی بیشمار است که میلیاردها ترانزیستور را در خود جای میدهد.

در اینجا یک مثال ساده باعث درک بهتری از بحث میشود. میخواهیم روش کار مدار جمعکنندهی یکبیتی را مرور کنیم. این مدار ۳ مقدار ورودی را دریافت میکند که شامل مقدار A، مقدار B و سیگنال Carry-In است و دو خروجی شامل مقدار Sum و سیگنال Carry-Out به دست میدهد. در طراحی مبنا از ۵ گیت منطقی استفاده میشود. این گیتها با یکدیگر لینک میشوند تا جمعکنندهای با هر اندازهی دلخواه بسازند. در طراحیهای مدرن پردازنده، اگرچه این فرایند با بهینهسازی برخی از مدارهای منطقی و سیگنالهای حامل داده، پیشرفتهای زیادی به خود دیده؛ اما اصول کار همچنان یکسان است.
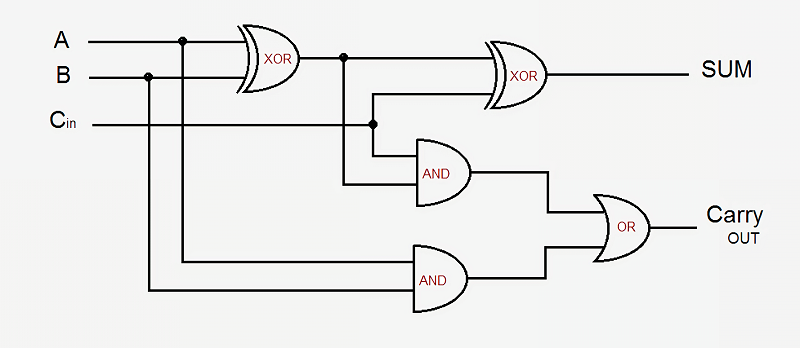 طرحی از یک مدار منطقی جمعکنندهی یک بیتی
طرحی از یک مدار منطقی جمعکنندهی یک بیتی
خروجی Sum در صورتی روشن میشود که یکی از مقادیر A یا B و نه هر دو روشن باشد یا سیگنال Carry-In وجود داشته و مقادیر A و B هر دو روشن یا هر دو خاموش باشد. سیگنال Carry-Out کمی پیچیدهتر است. این سیگنال وقتی فعال میشود که A و B هر دو در یک زمان روشن شود یا سیگنال Carry-In موجود باشد و یکی از دو مقدار A یا B روشن باشد. برای اتصال چند جمعکنندهی یک بیتی برای ساخت یک جمعکننده با پهنای بیشتر، فقط باید سیگنال Carry-Out بیت قبلی را به سیگنال Carry-In بیت جاری متصل کرد. هرچه مدارها پیچیدهتر باشد، ازدحام گیتهای کوچک منطقی بیشتر میشود؛ اما آنچه گفته شد، سادهترین راه برای جمعبستن دو عدد است. در پردازندههای مدرن از مدارهای جمعکنندهی پیچیدهتری استفاده میشود و بررسی چنین مدارهایی از حوصلهی این مقاله خارج است. پردازندهها علاوه بر مدارهای جمعکننده، دربرگیرندهی واحدهایی برای انجام عمل تقسیم، ضرب و نسخههای اعشاری تمامی این اعمال حسابی است.
ترکیب رشتهای از گیتها مشابه آنچه گفته شد، برای انجام پارهای از عملیاتها روی مقادیر ورودی با نام منطق ترکیبی شناخته میشود. با این حال، این نوع منطق تنها شیوهی شناختهشده در دنیای کامپیوترها نیست. اگر نتوان دادهها را ذخیره کرده یا وضعیت هر پارامتری را ردیابی کرد، استفاده از این شیوه چندان راهگشا نخواهد بود. برای اینکه امکان ذخیرهسازی دادهها وجود داشته باشد، از منطق ترتیبی استفاده میشود. منطق ترتیبی با اتصال دقیق وارونگرها و سایر گیتهای منطقی به نحوی انجام میپذیرد که خروجیهای هر گیت بازخوردی به ورودی آنها ارائه دهد. از این حلقههای بازخورد برای ذخیره کردن یک بیت داده استفاده میشود و با نام رم استاتیک یا SRAM شناخته میشوند. عبارت رم استاتیک در مقابل رم دینامیک در حافظههای DRAM قرار میگیرد؛ چرا که در نوع استاتیک، دادههای در حال ذخیره همواره بهطور مستقیم به ولتاژ مثبت یا زمین متصل هستند.
روش استاندارد برای پیادهسازی یک بیت واحد SRAM استفاده از ۶ ترانزیستوری است که در شکل زیر ترسیم شده است. سیگنال بالایی WL که مخفف عبارت Word Line است، آدرس بوده و زمانیکه اعمال شود، دادهی ذخیرهشده در این سلول یک بیتی به Bit Line که با حرف BL مشخص شده، ارسال میشود. خروجی BLB یا Bit Line Bar درست مقدار وارونشدهی Bit Line است. دو نوع ترانزیستور را در این مدار میتوان شناسایی کرد و دریافت که ترانزیستورهای M3 و M1 و در سوی دیگر M4 و M2 تشکیل یک گیت وارونگر را دادهاند.
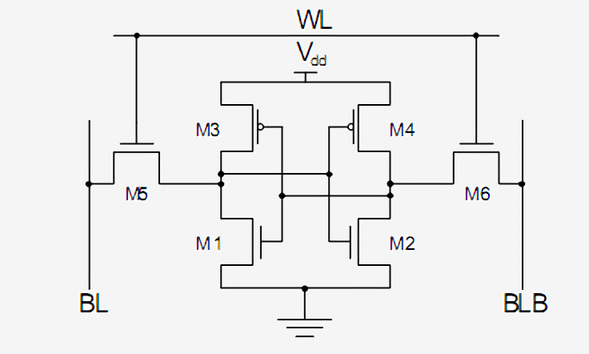 طرحی از یک مدار منطقی SRAM برای ذخیرهسازی یک بیت داده
طرحی از یک مدار منطقی SRAM برای ذخیرهسازی یک بیت داده
SRAM همان عنصری است که از آن برای ساخت حافظههای کشِ فوق سریع و ثباتهای درون پردازنده استفاده میشود. این عنصر اگرچه بسیار پایدار است، اما برای نگهداری یک بیت داده نیاز به ۶ تا ۸ ترانزیستور دارد؛ بنابراین ساخت چنین مداری از دیدگاه هزینه، پیچیدگی و فضای موجود در تراشه در مقایسه با DRAM بسیار گران تمام میشود. حافظههای رم دینامیک، در نقطهی مقابل، بهجای استفاده از گیتهای منطقی و ترانزیستورها برای ذخیرهی داده، از خازنهای بسیار ریز استفاده میکنند؛ این حافظهها را دینامیک مینامیم چرا که خازن مستقیم به جریان برق یا زمین متصل نیست و امکان تغییر ولتاژ آن بهصورت دینامیک وجود دارد. در این حافظهها تنها یک ترانزیستور واحد وجود دارد که از آن برای دسترسی به دادهی ذخیرهشده در خازن استفاده میشود.
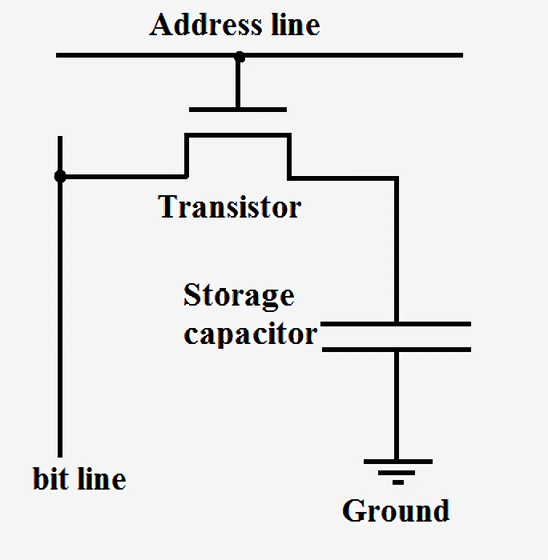 مدار حافظهی DRAM شامل یک ترانزیستور و یک خازن برای ذخیرهسازی یک بیت داده
مدار حافظهی DRAM شامل یک ترانزیستور و یک خازن برای ذخیرهسازی یک بیت داده
از آنجایی که حافظهی DRAM به ازای هر بیت داده تنها به یک ترانزیستور واحد نیاز دارد و طراحی آن بسیار مقیاسپذیر است، امکان ساخت حافظههای بسیار چگال و ارزانقیمت از این نوع وجود دارد. یکی از اشکالات رم دینامیک این است که ظرفیت شارژ خازن آنقدر کم است که بهطور دائم باید از نو شارژ شود. به همین دلیل است که وقتی کامپیوتر خود را خاموش میکنید، تمامی خازنها تخلیه میشود و هر آنچه در این حافظه بارگذاری شده، از دست میرود. ترکیبی از مدارهای کوچک شکل فوق در سطر و ستونهای پرشمار ساختار حافظهی DRAM سیستم را شکل میدهد.
شرکتهایی مثل اینتل، AMD و انویدیا طرحی دقیق از نحوهی کار پردازندههای خود ارائه نمیکنند، بنابراین نمایش دیاگرامی کامل از مدارهای منطقی یک پردازندهی مدرن ناممکن است؛ با وجود این، مثالی که از یک مدار جمعکنندهی ساده زده شد، میتواند تصور مناسبی از نحوهی کار یک پردازنده و چگونگی تجزیهی آن به گیتهای منطقی، عناصر ذخیرهسازی و در نهایت ترانزیستورها ایجاد کند.
اکنون که با روش کار و طرز ساخت بعضی از اجزای اساسی پردازندهها آشنا شدیم، باید دریابیم که چگونه همهی اجزا به یکدیگر متصل و با یکدیگر همگام میشوند. همه اجزای کلیدی یک پردازنده به عاملی با نام سیگنال کلاک متصل میشوند. این سیگنال در بازههای از پیش تعریفشده با نام فرکانس، بین دو حد بالا و پایین نوسان میکند. سیگنال کلاک توسط قطعهای با نام مولد سیگنال (Signal Generator) که یک نوسانساز الکترونیکی است، تولید میشود. نوسانساز متشکل از برد مدارات پیزوالکتریک از جنس کوارتز یا سرامیک است. این مولد، سیگنالی با زمانبندی دقیق برای همگامسازی عملکرد مدارهای منطقی مختلف درون تراشه تولید میکند. مولد سیگنال سینوسی را در ورودی دریافت کرده و طی مراحلی آن را تبدیل به یک موج مربعی سادهی متقارن یا موج پیچیدهتری میکند و تحویل تراشه میدهد.
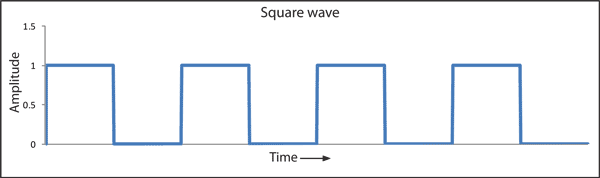 سیگنال کلاک ایدهآل یک پردازندهی کامپیوتری که به شکل یک موج مربعی تکرار شونده بین دو مقدار (ولتاژ) بالا و پایین است
سیگنال کلاک ایدهآل یک پردازندهی کامپیوتری که به شکل یک موج مربعی تکرار شونده بین دو مقدار (ولتاژ) بالا و پایین است
اجزای منطقی پردازنده همگام با اوج و فرود سیگنال دریافتی، مقادیر را تبدیل و جایگزین (سوییچ) کرده و محاسبات را اجرا میکنند. با همگامکردن تمامی اجزا با یکدیگر میتوان اطمینان یافت که دادهها همواره با زمانبندی مناسبی تحویل و دریافت میشود، بهطوریکه هیچ خللی در کار پردازنده پدید نمیآید.
خوانندگان این مقاله ممکن است با مفهوم اورکلاکینگ آشنا باشند که در آن کلاک پردازنده بهطور دستی یا از طریق متدهای نرمافزاری افزایش مییابد تا سطح عملکرد تراشه بهبود یابد. این بهبود سطح عملکرد ناشی از تسریع فرایند سوئیچ ترانزیستورها و مدارهای منطقی با سرعتی بیشتر از آن چیزی است که در طراحی پیشبینی شده است. از آنجایی که در هر ثانیه سیکلهای کلاک بیشتری پیموده میشود، کار بیشتری قابل انجام است و پردازنده کارایی بالاتری دارد؛ هرچند این افزایش سطح عملکرد نقطهی بیشینهای دارد. فرکانس یا سرعت کلاک پردازندههای مدرن عددی بین ۳ تا ۴/۵ گیگاهرتز است و در طول یک دهه گذشته این رقم تغییر چندانی به خود ندیده است. درست همچون یک زنجیر فلزی که استحکام آن برابر با استحکام ضعیفترین حلقه است، حداکثر سرعت کلاک عملیاتی یک پردازنده را کندترین بخش آن مشخص میکند. هر جزء واحد پردازنده با پایان یافتن یک سیکل کلاک بایستی عملیات مقرر را به اتمام رسانده باشد. اگر در این بازهی زمانی بخشی از پردازنده قادر به تکمیل عملیات در حال اجرا نباشد، فرکانس کلاک برای آن پردازنده بیشتر از ظرفیت آن بوده و تراشه در این شرایط از کار بازخواهد ایستاد. طراحان این کندترین بخش تراشه را مسیر بحرانی (Critical Path) مینامند و این بخش تعیینکنندهی حداکثر فرکانس یک پردازنده است. تجاوز از یک فرکانس معین سبب میشود، ترانزیستورها با سرعت کافی سوئیچ نشوند و اختلال در روند کار یا تولید خروجیهای نادرست آغاز شود.

فرایند سوئیچ ترانزیستورها را میتوان با افزایش ولتاژ تغذیه پردازنده تا حد معینی افزایش داد و افزایش بیش از حد ولتاژ خود ممکن است عامل ایجاد اختلال باشد. از سویی، افزایش بیش از حد ولتاژ خطر سوختن پردازنده را در پی دارد. با افزایش هر یک از دو عامل فرکانس یا ولتاژِ یک پردازنده گرمای بیشتری تولید میشود و توان مصرفی افزایش مییابد. علت این است که توان پردازنده مستقیماً متناسب با فرکانس (سرعت کلاک) و مجذور ولتاژ تغذیه است. برای تعیین توان مصرفی یک پردازنده، معمولاً هر ترانزیستور را به مثابهی یک خازن کوچک تصور میکنیم که هنگام تغییر مقادیر، باید شارژ یا دشارژ شود.
تحویل توان پایدار به پردازنده گاه آنقدر مهم است که نیمی از پینهای فیزیکی روی تراشه، تنها برای تأمین توان مصرفی مورد استفاده قرار میگیرد یا نقش اتصال زمین را ایفا میکند. بعضی تراشهها ممکن است حین بارگذاری کامل بیش از ۱۵۰ آمپر جریان بکشند و هر میلیآمپر از این جریان باید با دقت و ظرافت زیادی مدیریت شود. در بیان حساسیت حجم توان مصرفی تراشه همین بس که هر پردازنده در واحد سطح میزان گرمایی بیشتر از یک راکتور هستهای تولید میکند.
سیگنال کلاک در پردازندههای مدرن رقمی در حدود ۳۰ تا ۴۰ درصد مجموع توان مصرفی تراشه را به خود اختصاص میدهد؛ چرا که این تولید و حفظ و بهرهبرداری از این سیگنال بسیار پیچیده است و باید بخشهای مختلف زیادی را به کار اندازد. برای صرفهجویی در مصرف انرژی، در طراحیهایی با بهرهوری بالا اجزایی از تراشه که در حال استفاده نیست، خاموش میشود. این کار با خاموشکردن سیگنال کلاسیک در ورودی آن جزء (Signal Gating) یا قطع دسترسی به توان (Power Gating) عملیاتی میشود.
سیگنال کلاک چالش دیگری در طراحی پردازنده نیز به بار میآورد. با افزایش مداوم فرکانس کلاک پردازندهها، موانع ناشی از قوانین فیزیک بیشتر میشود. اگر میتوانستیم سیگنال کلاک را به یک سر تراشه متصل کنیم، در آن واحد سیگنال از سمت دیگر خارج میشد و فرصتی برای همگامسازی اجزا پدید نمیآمد. برای همگامسازی تمام اجزای تراشه، سیگنال کلاک با استفاده از ساختاری به نام H-Tree در سراسر تراشه توزیع میشود. این ساختار تضمین میکند که تمامی نقاط انتهایی، فاصلهی یکسانی از مرکز داشته باشند.
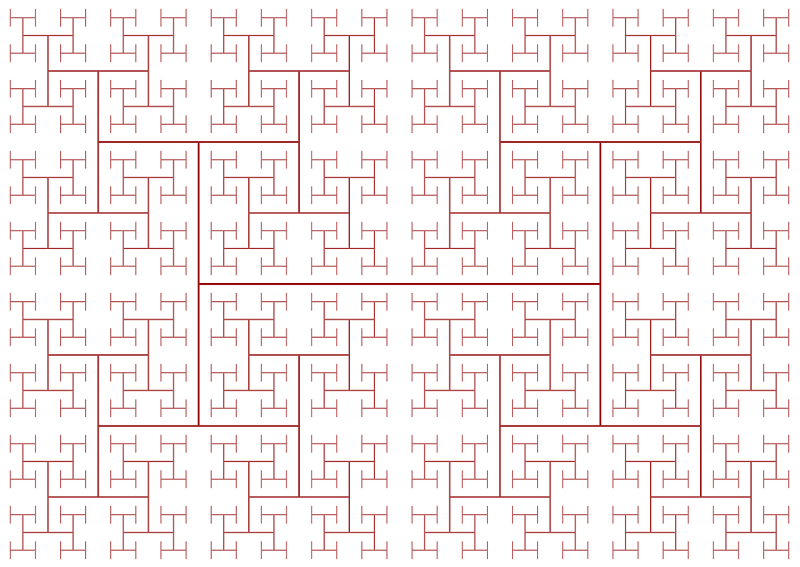 ساختار H-Tree برای حفظ و توزیع سیگنال کلاک در سطح پردازنده
ساختار H-Tree برای حفظ و توزیع سیگنال کلاک در سطح پردازنده
شاید طراحی تک به تک ترانزیستورها، سیگنال کلاک و اتصال توان در یک تراشه کاری بسیار پیچیده و ملال آور به نظر برسد و در حقیقت هم همینطور است. شرکتهایی مثل اینتل، کوالکام و AMD هزاران مهندس طراح تراشه دارند، اما حتی برای آنها هم طراحی تمامی جنبههای عملی یک تراشه ناممکن است. این شرکتها برای طراحی پردازندههای خود با آن گستردگی عظیم، از ابزارهای مختلف پیچیدهای استفاده میکنند تا طراحیها و شماتیکهای مدار مورد نظر را برای آنها خلق کنند. این ابزارها شرح سطح بالایی از آنچه که هر یک از اجزای تراشه باید انجام دهد دریافت میکنند و در نهایت بهینهترین پیکربندی سختافزاری را برای برآوردهکردن الزامات و سطح عملکرد مورد نظر به دست میدهند. تراشهسازان به سمت تکنیک جدیدی به نام High Level Synthesis گرایش یافتهاند. این تکنیک به توسعهدهندگان اجازه خواهد داد تا سطح عملکرد مورد نظر خود را در قالب کدهایی بیان کنند و سپس کامپیوترها نحوهی دستیابی بهینه به سختافزار مورد نظر را میسنجند و در اختیار مهندسان قرار میدهند.
تراشهسازان تلاش میکنند عیوب تراشه را در مرحله بررسی و اعتبارسنجی طراحیها، پیش از رسیدن به خط تولید برطرف کنند؛ اگر عیوب به تراشه فیزیکی منتقل شود، دیگر قابل رفع نیستند
درست همانطور که برنامهنویسان برنامههای کامپیوتری را از طریق کدها تعریف میکنند، طراحان هم میتوانند سختافزار را از طریق کد تعریف و شناسایی کنند. زبانهای برنامهنویسی بهمانند Verilog و VHDL توسعه یافته است که به طراحان سختافزار اجازه میدهد، سطوح عملکرد مدارهای منطقی در حال ساخت را به زبانی قابل فهم برای ماشین بیان کنند. در مرحلهی بعد شبیهسازی، بررسی و اعتبارسنجی این طراحیها انجام میپذیرد و اگر همهچیز مورد تأیید باشد، امکان سنتز و همگذاری ترانزیستورهای خاص برای ساختن مدارات مورد نظر فراهم میشود. روند بررسی و اعتبارسنجی شاید به اندازهی طراحی یک هسته یا قطعهی کش جدید درخور توجه به نظر نرسد، اما به لحاظ منطقی از اهمیت بیشتری برخوردار است. به ازای هر مهندس طراحی که یک شرکت استخدام میکند، ممکن است پنج مهندس بررسیگر یا حتی بیشتر از آن استخدام شود.
بررسی و اعتبارسنجی یک طراحی جدید معمولاً زمان و هزینهی بیشتری در مقایسه با ساخت تراشهی فیزیکی واقعی میبرد. شرکتها زمان و پول زیادی را صرف بررسی و اعتبارسنجی طراحیها میکنند؛ چرا که به مجرد آنکه تراشهای به مرحله تولید رسید، دیگر فرصتی برای رفع عیوب احتمالی آن وجود ندارد. ایرادهای نرمافزاری با انتشار وصلهها قابل رفع است، اما برای رفع ایرادهای سختافزاری غالباً راهکاری وجود ندارد. برای مثال اینتل در واحد تقسیم اعشاری برخی از پردازندههای پنتیوم خود باگی دارد که تا به امروز دو میلیارد دلار هزینه روی دستشان گذاشته است.
از دیدگاهی فراتر، تصور ساخت یک تراشهی بسیار پیچیده با میلیاردها ترانزیستور و آنچه که همه آنها در کنار هم انجام میدهند، بسیار سخت جلوه میکند. با وجود این اگر براساس دانستههایی که از این مقاله به دست آوردیم، هر پردازنده را مجموعهای از اجزای سادهتر تصور کنیم که هر یک وظیفهای با پیچیدگی کمتر را انجام میدهد، حل مسئله آسانتر میشود. ترانزیستورها گیتهای منطقی را میسازند، ترکیبی از گیتهای منطقی باعث تشکیل واحدهای عملیاتی میشود که هر یک وظیفهی خاصی را اجرا میکنند و در نهایت این واحدهای عملیاتی به یکدیگر میپیوندند تا معماریهای دستورالعملی را که در این مقاله در مورد آنها صحبت کردیم، پیادهسازی کنند.
در قسمت دوم مقاله در مورد روشهای ساخت فیزیکی تراشههای پردازنده و فناوریهای ساخت آنها صحبت خواهیم کرد و با خطمشیهای کنونی و آیندهی توسعهی معماریهای کامپیوتری آشنا خواهیم شد.
:: بازدید از این مطلب : 876
|
امتیاز مطلب : 0
|
تعداد امتیازدهندگان : 0
|
مجموع امتیاز : 0





